1. Diffusion Model 정의
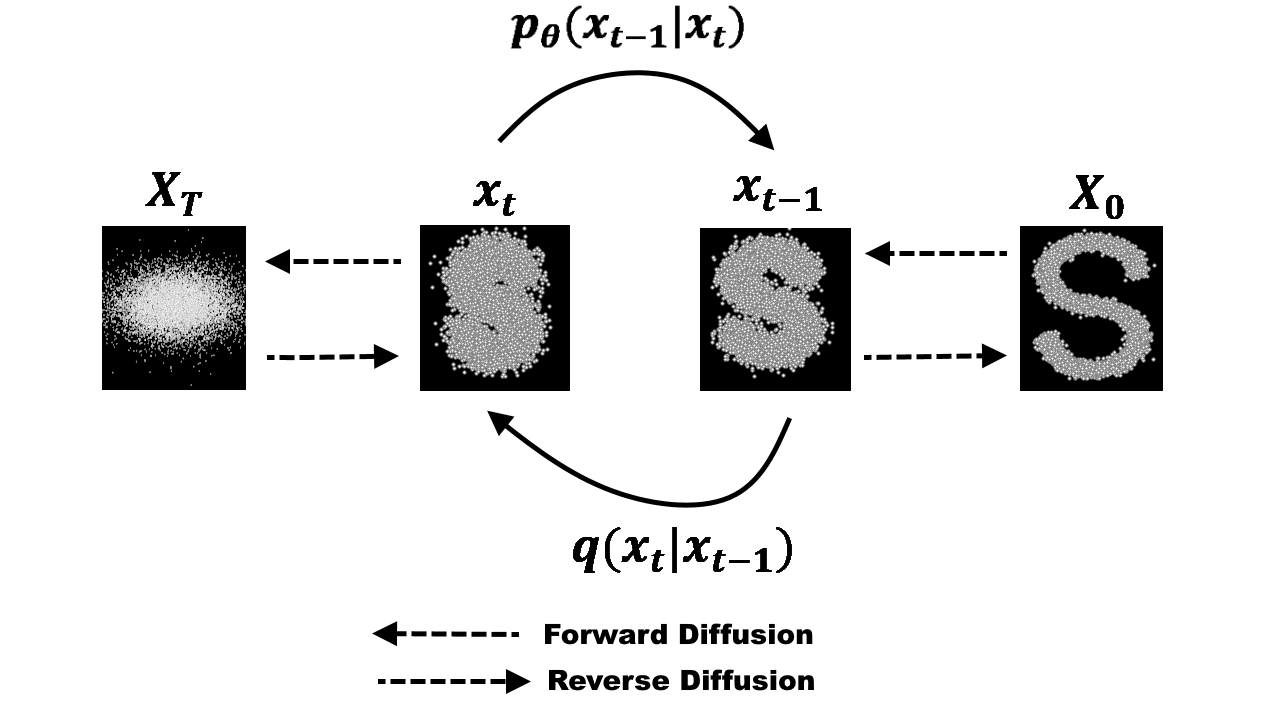
diffusion model은 원본 샘플 \(x_0 \sim q(x_0)\)를 \(T\) step 에 걸쳐서 Gaussian Noise를 준 \(x_T\)가 Gaussian 분포를 따른다고 가정하고, 해당 변환의 역과정을 학습해서 원본 샘플의 분포에서 샘플링할 수 있도록 하는 생성 모델의 일종이다.
diffusion process를 수식으로 표현하면 다음과 같다.
$$ q(x_t | x_{t-1}) = \mathcal{N}(x_t; \sqrt{1- \beta_t} x_{t-1}, \beta_t I) $$
수식에는 Gaussian Noise를 각 스텝에서 얼마나 넣어주고, 기존 피쳐를 얼마나 희석할지를 정하는 파라미터 \( \beta_t \in (0,1) \)가 있다. \( \beta_t \)값이 커질수록 기존 피처가 줄어들고 노이즈는 많이 첨가된다. 일반적으로 스텝 초반에는 적은 beta값으로 시작해 학습 후반으로 갈수록 커져도 괜찮다고 한다. 즉, \( \beta_1 \lt \beta_2 \lt ... \lt \beta_T \) 이다.
이렇게 diffusion을 정의하면 장점이 있는데 주어진 샘플 \( x_0 \)에 대해 임의의 스텝 \( t \)의 분포에서 샘플링이 가능하다. 필요하다면 \( \mu \)와 \( \Sigma \)의 학습을 위해 reparametrization trick도 사용 가능하다.
$$ x_t = \sqrt{1-\beta_t} x_{t-1} + \sqrt{\beta_t} z_{t-1} $$
$$ x_t = \sqrt{\alpha_t} x_{t-1} + \sqrt{1-\alpha_t} z_{t-1} \textrm{ , where } \alpha_t := 1-\beta_t $$
$$ x_t = \sqrt{\alpha_t} (\sqrt{\alpha_{t-1}} x_{t-2} + \sqrt{1-\alpha_{t-1}} z_{t-2}) +\sqrt{1-\alpha_t} z_{t-1} $$
$$ x_t = \sqrt{\bar{\alpha}_t} x_{0} + \sqrt{1- \bar{\alpha}_t} z_0 \textrm{ , where } \bar{\alpha}_t := \Pi_{i=1}^{t} \alpha_i $$
여기에서 \( \forall t \textrm{, } z_t \sim \mathcal{N}(0,I) \) 이므로, 분산이 다른 두 Gaussian 분포 \( \mathcal{N}_1 \sim N(0, \sigma_1 I), \mathcal{N}_2 \sim N(0, \sigma_2 I) \)의 합은 \( \mathcal{N}(0, (\sigma_1^2 + \sigma_2^2) I ) \) 를 따른다는 점을 이용했다.
2. Reverse Diffusion Process
그런데 생성 모델 관점에서 관심있는 것은 diffusion이 아니라 reverse diffusion이다. 해당 분포인 \( q(x_{t-1} | x_{t}) \) 는 \( \beta_{t-1} \)이 충분히 작다면 Gaussian 분포에 가까울 것이라는 가정은 할 수 있지만 (Why? continuous diffusion model에서는 beta가 0으로 갈 때 역변환이 normal인게 알려져 있다고 함) 정확한 분포를 구할 수는 없다. 그래서 해당 분포를 근사하는 매개화된 분포 \( p_\theta ( x_{t-1} | x_t ) \sim \mathcal{N} (x_{t-1}; \mu_\theta(x_t, t), \Sigma_\theta(x_t, t)) \) 를 구하려고 한다.
이 분포의 매개변수 \( \theta \)를 어떻게 학습할 수 있을까? Evidence를 직접 최대화 할 수 있으면 좋겠지만 계산이 불가능하기 때문에 Normal 가정을 가지고 해석적으로 표현 가능한 Variational Lower Bound(VLB)를 대신 사용한다. 여기에서 활용하는 부분은 \( q(x_{t-1} | x_t ) \) 는 intractable하지만 \( q(x_{t-1} | x_{t}, x_0) \) 는 계산이 가능하다는 것이다.
해석적으로 표현 가능한 reverse process
$$ q(x_{t-1} | x_t, x_0) = q(x_t | x_{t-1}, x_0) \frac{q(x_{t-1} | x_0)}{q(x_t | x_0)} $$
$$ = q(x_t | x_{t-1}) \frac{q(x_{t-1} | x_0)}{q(x_t | x_0)} \quad \textrm{since} \quad x_0 \perp x_{t} | x_{t-1} $$
$$ \propto \exp \Big( -\frac{1}{2} \Big(\frac{(x_t - \sqrt{\alpha_t} x_{t-1})^2}{\beta_t} + \frac{(x_{t-1} - \sqrt{\bar{\alpha}_{t-1}} x_0)^2}{1- \bar{\alpha}_{t-1}} - \frac{(x_{t} - \sqrt{\bar{\alpha}_{t}} x_0)^2}{1- \bar{\alpha}_{t}} \Big) \Big) $$
$$ = \exp \Big( - \frac{1}{2} \Big( (\frac{\alpha_t}{\beta_t} + \frac{1}{1-\bar{\alpha}_{t-1}}) x_{t-1}^2 - ( \frac{2 \sqrt{\alpha_t} }{\beta_t} x_t + \frac{2\sqrt{\bar{\alpha}_t}}{1-\bar{\alpha}_t} x_0) x_{t-1} + C(x_t, x_0) ) \Big) \Big) $$
pdf가 \(x\)에 대한 2차식의 지수함수 형태이므로 normal 분포를 따른다. 즉, \( x_0 \) 를 컨디셔닝하면 reverse process도 normal 분포로 표현이 가능하다.
$$ q(x_{t-1} | x_{t}, x_0) \sim \mathcal{N} (x_{t-1}; \tilde{\mu}_t(x_t, x_0), \tilde{\beta}_t(x_t, x_0)) $$
$$\textrm{where}\quad \tilde{\beta} = \frac{1-\bar{\alpha}_{t-1}} { 1- \bar{\alpha}_{t}} \beta_t, \quad \tilde{\mu} = \frac{1}{\sqrt{\alpha_t}} \Big( x_t - \frac{\beta_t}{\sqrt{ 1- \bar{\alpha}_t}}z_t \Big) $$
Variational Lower Bound
$$ - \log p(x_0) \leq- \log p(x_0) + D_{KL} (q(x_{1:T} | x_0) | p(x_{1:T} | x_0 )) \\ = - \log p(x_0) + \mathbb{E}_{x_{1:T} \sim q(x_{1:T} | x_0)} \Big[ \log \frac{q(x_{1:T} | x_0 )}{p_\theta (x_{0:T}) / p_\theta(x_0) } \Big] \\ = - \log p(x_0) + \mathbb{E}_q \Big[ \log \frac{q(x_{1:T} | x_0 )}{p_\theta (x_{0:T}) }+ \log p_\theta (x_0) \Big] \\ = \mathbb{E}_q \Big[ \log \frac{q(x_{1:T} | x_0 )}{p_\theta (x_{0:T}) }\Big] = \mathbb{L}_{\textrm{VLB}}$$
위의 \( \mathbb{L}_{\textrm{VLB}} \) 를 최소화 하는 방식으로 학습을 진행하여 매개변수를 학습할 수 있다. VLB Loss는 아래와 같이 KL divergence의 summation으로 표현할 수 있다.
$$ L_\text{VLB} = L_T + L_{T-1} + \dots + L_0 \\ \textrm{where } L_T = D_\text{KL}(q(\mathbf{x}_T \vert \mathbf{x}_0) \parallel p_\theta(\mathbf{x}_T)) \\ L_t = D_\text{KL}(q(\mathbf{x}_t \vert \mathbf{x}_{t+1}, \mathbf{x}_0) \parallel p_\theta(\mathbf{x}_t \vert\mathbf{x}_{t+1})) \text{ for }1 \leq t \leq T-1 \\ L_0 = - \log p_\theta(\mathbf{x}_0 \vert \mathbf{x}_1) $$
Simplification
$$L_t = \mathbb{E} \Big[ \frac{1}{2 {\| \Sigma_\theta (x_t,t) \|}_2^2} \| \tilde{\mu}(x_t, x_0) - \mu_\theta (x_t, t) \|^2 \Big] \\ = \mathbb{E} \Big[ \frac{ \beta_t^2 }{2 \alpha_t (1-\bar{\alpha}_t) {\| \Sigma_\theta \|}_2^2} \| z_t - z_\theta (x_t, t) \|^2 \Big]\\ \rightarrow L_t^{\textrm{simple}} = \mathbb{E} \Big[ \| z_t - z_\theta (x_t, t) \|^2 \Big] $$
3. \( \beta_\theta \)와 \( \mu_{\theta} \)
beta
\( \beta_t \) 는 다음 timestep으로 갈때 노이즈가 섞이는 양으로 직관적으로 이해할 수 있다. 엄밀하게 말하면 매개화를 한다기보다는 scheduling의 개념에 가깝다. 보통 뒤쪽으로 갈 수록 더 많은 노이즈가 섞이도록 \(\beta_t\)를 monotinocally increasing 하게 한다.
이 과정에서 \( \bar{\alpha}_t = \prod_{i \leq t} (1 - \beta_i) \)는 감소하게 되는데
Nichol & Dhariwal(2021) 에서는 linear scheduling 보다 cosine scheduling이 좋다고 보고하고 있다.
Sigma
$$\boldsymbol{\Sigma}_\theta(\mathbf{x}_t, t) = \exp(\mathbf{v} \log \beta_t + (1-\mathbf{v}) \log \tilde{\beta}_t) $$
이렇게 표현하면 Reweighted VLB Loss 안에는 \(\Sigma\)의 parameter가 포함되지 않기 때문에 원래 VLB Loss를 조금 섞어준다.
$$ L_{\textrm{hybrid}} = L_{\textrm{simple}} + \lambda L_{\textrm{VLB}}, \quad \lambda = 0.001 $$
4. Diffusion Model의 장단점
GAN과 같은 기존 생성모델과 달리 latent feature가 원본 차원과 동일하므로 high resolution image 등에 적용하기 좋다는 장점이 있다. 단점은 샘플링을 위해 T step의 연산을 거쳐야 하기 때문에 샘플링 효율이 매우 안 좋다는 점이다. 이를 개선하기 위해 Sampling step 수를 Striding을 통해 줄이면서 mean만 활용해서 deterministic sampling한 연구가 있다.
Reference
https://lilianweng.github.io/posts/2021-07-11-diffusion-models/



댓글
댓글 쓰기